
What’s the best way to follow up a week of Oracle OpenWorld? Cloudera Developer Training for Apache Hadoop of course.
So today I had my first day. I won’t detail the course itself (though I hope there will be many Hadoop posts to come). But I would like to share three of the things I learned today.
DISCLAIMER: I’d like to stress that I learned these things today. If anything in this blog post is factually inaccurate please calmly proceed to the comments section and let me know so I can fix it and learn more. Or if you’re having a bad day and need to vent you can give me the ol’ what for. I can take it.
The Famous Word Count Reducer Example Sets a Weak Tone
This isn’t about the course, but what you’ll find on the web with regards to Hadoop and MapReduce. Usually when you’re looking up MapReduce examples the first thing you’ll find is one with a list of fruit or animals or something else and an example of how a MapReduce job can find the number of occurrences of each word and then sum up the counts per word. So for instance:
Input
apple banana apple orange
banana orange apple apple
apple banana banana
Mapper
- Accept the input as key:value pairs (key is the character position number of each newline, value is each line)
- Loop through the array of key:line pairs
- Emit key:value pairs of words as keys, and ‘1’ as value for each time it shows up
So in this case it would emit something like [apple:1, banana:1, apple:1, orange:1, banana:1, orange:1, apple:1, apple:1, apple:1, banana:1, banana:1].
Reducer
- Accept the input of key:value pairs (words and the number ‘1’ for each occurrence)
- Loop through the input array
- Sum up the 1’s (value) per word (key)
- Return the results for the final hoorah
In this case, the final output would be [apple:5,banana:4,orange:2]
Simple, right? The problem for me is that it doesn’t capture the complexity and power of Hadoop and MapReduce well enough. I get that this is like the ‘Hello World’ of MapReduce jobs. But I still feel it sets a weak tone compared to other software packages I’ve seen, particularly to beginners. Where’s the excitement of a dozen or more DataNodes churning through the Map phase? Where’s the promise of a medical and espionage technological revolution I’ve heard so much about? Where, pray tell, is the big data?
Remember that MapReduce jobs can be written in many different languages (Java is the original but not the only one) and can use all the tools of that language. If you’re writing in Java and want to parse text, go for it.  If you want to convert image formats and keep track of sizes or conversion time, feel free. If you’re writing in PHP or node.js or Python and want to pull extra information from webservices to compare against, be my guest (but don’t bottleneck your job). These Mapper and Reducer classes are generally small and lightweight, but remember that you can do any programming magic you desire in them. It’s up to you and your imagination.
If you want to convert image formats and keep track of sizes or conversion time, feel free. If you’re writing in PHP or node.js or Python and want to pull extra information from webservices to compare against, be my guest (but don’t bottleneck your job). These Mapper and Reducer classes are generally small and lightweight, but remember that you can do any programming magic you desire in them. It’s up to you and your imagination.
That being said, the Cloudera Quick Start VM is awesome. It’s free to download and comes preconfigured with Cloudera Manager, HDFS, Hive, Hue, MapReduce, Oozie, ZooKeeper, Flume, HBase, Cloudera Impala, Cloudera Search, and YARN. It even comes with example queries and scripts. If you’re really wanting to find out what Hadoop and MapReduce are about, I’d recommend starting with it.
Hadoop Can Be Fairly Breakable
While Hadoop is awesome in its ability to scale and provide fault tolerance at the DataNode level through block replication, the overall system is fairly weak thanks to the single points of failure on the NameNode. The NameNode itself is a single point of failure, though Hadoop 0.23 and higher can have a Secondary NameNode. On the NameNode comes the JobTracker which is also a single point of failure. However, from what I understand MapReduce 2 will help alleviate that a bit.
 Also, even though you use the Hadoop Filesystem (HDFS) for putting and getting data, that filesystem is really just a virtual filesystem over a share-nothing cluster of local filesystems on your DataNodes. Even though access into the HDFS files is governed by the ‘hadoop’ binary or other APIs, you can log into a DataNode and remove data blocks fairly easily. I’m not saying this is a flaw; hell, you could do the same with Oracle, where any ‘dba’ user can overwrite and tear up a database. In fact, Oracle is more susceptible due to the lack of block replication. But it’s still worth noting.
Also, even though you use the Hadoop Filesystem (HDFS) for putting and getting data, that filesystem is really just a virtual filesystem over a share-nothing cluster of local filesystems on your DataNodes. Even though access into the HDFS files is governed by the ‘hadoop’ binary or other APIs, you can log into a DataNode and remove data blocks fairly easily. I’m not saying this is a flaw; hell, you could do the same with Oracle, where any ‘dba’ user can overwrite and tear up a database. In fact, Oracle is more susceptible due to the lack of block replication. But it’s still worth noting.
Third is security. By default the security of writing and running jobs in Hadoop sucks. If you really want good security you need to configure it with kerberos. Apparently this has been well discussed.
Hadoop is Just the Beginning
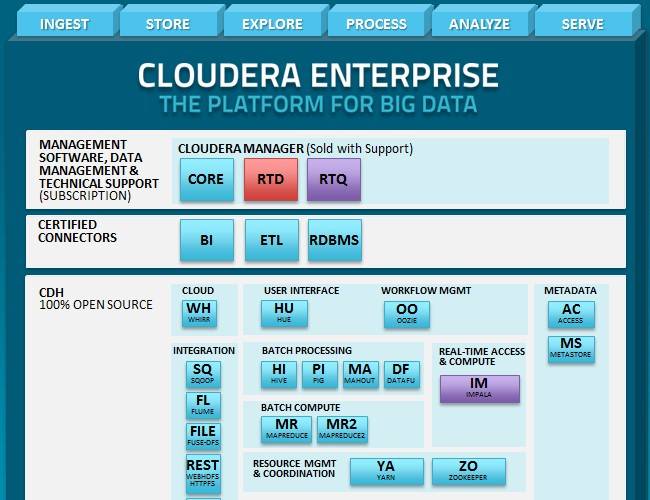 Being the horrible student that I am, I took some time to delve into other software on my first day such as Hue, Hive, HBase, and Pig. Hue is pretty awesome as a UI to the ecosystem as a whole, not much to say there. But looking at Hive and Pig specifically, tinkering a bit with some PigLatin, and playing with some sample data in Hive got me realizing that understanding HDFS and MapReduce are things I really need to do…so I can move onto learning more.
Being the horrible student that I am, I took some time to delve into other software on my first day such as Hue, Hive, HBase, and Pig. Hue is pretty awesome as a UI to the ecosystem as a whole, not much to say there. But looking at Hive and Pig specifically, tinkering a bit with some PigLatin, and playing with some sample data in Hive got me realizing that understanding HDFS and MapReduce are things I really need to do…so I can move onto learning more.
My current set of goals are to finish the course, take my Cloudera Certified Developer for Apache Hadoop (CCDH) exam, and starting learning Pig and Mahout. However, from what I can tell this will be my favorite kind of learning experience: one with a twist at every new finding. The kind of weekend project that turns into a week project, then multi-week, then consumes you until you realize, “Hey, I know this crap.”
Wish me luck.
Nice blog| I have gained good knowledge about Hadoop.
Nice article, it is very valuable helpful and informative for me. Thanks for sharing these information with all of us.
Bigg Boss 17th season will go on the floor day from 3 October 2023. The online application form
Following the format of the show, Bigg Boss 17 celebrity contestants will be locked in a house.
absolutely loved it.thanks
Comprar carta de condução
Work hard and get up top…. https://kupie-prawo-jazdy.com/
Get it done really fast… https://kupiprawojazdy.com/
All in one, we can get there with more effort… https://comprar-carnet-deconducir.com/
No sleep i do only naps… https://koupi-tridicskyprukaz.com/
Give it up for the one in form now… https://geregistreerdrijbewijskopen.com/
Help get it all the way to the top… https://acheter-permis-de-conduire.com/
let’s try that again this time with more pressure… https://kupiti-vozaku-dozvolu.com/
Try a different approach to this problem… https://comprar-cartadeconducao.com/
Just work a little bit harder than before…. https://acquistapatentediguida.com/
The same process all through but a different approach…. https://comprare-la-patente.com/
Make it make sense to me, we are going all out…. https://kjopeforerkort.com/
Let us try to make things go smoothly… https://dokumenteanzeigen.com/
https://rijbewijskopenc.com/
https://comprarepatenteb.com/
https://pinballplayhouse.com/
Mit uns müssen Sie nicht nach Deutschland reisen, um Ihren Führerschein zu bekommen. Wir machen Ihnen das Leben leichter und Sie können Ihren Führerschein von zu Hause aus machen, ohne Reiseantrag, Fahrschule, Gesundheitschecks und mindestens 6 Monate Aufenthalt. Vertrauen Sie uns, unsere deutschen Führerscheine sind in Datenbanken registriert und Sie können mit Ihrem neuen Führerschein in der gesamten EU frei fahren. Führerschein Kaufen.
https://echtenfuhrerscheinkaufen.com/
Véritable permis de conduire et inscrit sur notre site internet sans passer aucun examen ni passer l’examen pratique.
tout ce dont nous avons besoin, ce sont vos coordonnées et elles seront enregistrées dans le système dans les huit prochains jours.
Le permis de conduire doit passer par la même procédure d’enregistrement que ceux délivrés dans les auto-écoles,
https://acheterpermisdeconduirelegal.com/
Dobrý den, vítejte v p?ední sv?tové organizaci ?idi?ských pr?kaz?.
Prodáváme legální a registrované ?eské ?idi?ské pr?kazy registrované ve vládním databázovém systému i v r?zných autoškolách, se kterými spolupracujeme. Všichni víme, že jako ?eský ob?an lze získat ?eský ?idi?ský pr?kaz po absolvování kurzu ?idi?ské výchovy a složení dvoustup?ové zkoušky: teoretické a ?idi?ské.
https://koupitridicsky-prukaz.com/
Maine Coon Kittens available for Rehoming. Maine Coon kittens are known for their large size, friendly personalities, and striking appearance.
Originating from the state of Maine in the United States, these gentle giants are one of the oldest and most popular cat breeds in the world and they make excellent companions for families and individuals alike.
https://mainecoonrehoming.com/
Hermosos cachorros para adopción. El mejor lugar para conseguir tus adorables y bien entrenados cachorros.
Al adoptar, no solo consigues un amigo fiel, sino que también ayudas a combatir la sobrepoblación en los refugios, dándole una segunda oportunidad a un cachorro que, de otro modo, podría enfrentar un futuro sombrío. Es fundamental considerar diversos factores, como la raza, el tamaño y el temperamento del cachorro, para asegurar que se adapte a tu estilo de vida.
https://adopciondecachorros.com/
Prawdziwe prawo jazdy i rejestracja na naszej stronie internetowej bez konieczno?ci zdawania egzaminu lub egzaminu praktycznego.
Wystarczy poda? swoje dane, a wniosek zostanie zarejestrowany w systemie w ci?gu najbli?szych o?miu dni.
Prawo jazdy musi przej?? t? sam? procedur? rejestracji, co prawo jazdy wydawane w szko?ach nauki jazdy.
https://kuplegalne-prawojazdy.com/
Riktigt körkort registrerat på vår webbplats utan att ha gjort något prov eller gjort det praktiska provet.
Allt vi behöver är dina uppgifter och de kommer att loggas in i systemet inom de närmaste åtta dagarna.
Körkortet måste genomgå samma registreringsprocedur som de som utfärdas på trafikskolor,
https://kopalagligtkorkort.com/
Carta de condução verdadeira e registada no nosso site sem ter de fazer nenhum exame ou teste prático.
tudo o que precisamos são os seus dados e serão registados no sistema dentro dos próximos oito dias.
A carta de condução deve passar pelo mesmo procedimento de registo das emitidas nas escolas de condução,
https://cartadeconducao-legal.com/
Bine a?i venit pe site-ul nostru oficial, unde oferim un serviciu de ob?inere a permisului de conducere românesc f?r? examen.
Dup? plasarea comenzii, ve?i fi contactat de personalul companiei, iar comanda dumneavoastr? va fi procesat? în termen de 7 zile lucr?toare.
Cump?ra Permis De Conducere.
Ave?i încredere în noi, permisele noastre de conducere române?ti sunt înregistrate în baze de date ?i pute?i conduce liber cu noul permis de conducere în întreaga UE.
https://cumpara-permisdeconducerelegal.com/
Ekte førerkort registrert på nettsiden vår uten å ta noen eksamen eller praktisk prøve.
Alt vi trenger er dine opplysninger, og de vil bli logget inn i systemet innen de neste åtte dagene.
Førerkortet må gå gjennom samme registreringsprosedyre som de som utstedes på kjøreskoler,
https://kjop-lovligforerkort.com/
https://comprarcarnetdeconducira.com
http://kupprawojazdyb.com
https://comprarepatenteb.com
Se você se deparar com esta mensagem buscando comprar uma carteira de motorista registrada sem os exames então estamos aqui para ajudá-lo, basta clicar no link abaixo para falar com um agente. o agente irá orientá-lo sobre como obter a carteira de motorista
Se você tiver dúvidas sobre como obter uma carteira de motorista, recomendamos procurar informações diretamente em fontes oficiais. Através dos canais adequados, você poderá receber orientações claras sobre os requisitos, exames necessários e todo o processo de emissão de forma legal e segura.
Als u dit bericht tegenkomt waarin u probeert een geregistreerd rijbewijs te kopen zonder de examens, dan staan ??wij voor u klaar. Klik eenvoudig op de onderstaande link om met een agent te praten. de agent zal u begeleiden bij het verkrijgen van het rijbewijs
Pokud narazíte na tento inzerát, ve kterém se snažíte koupit registrovaný ?idi?ský pr?kaz bez složení zkoušek, jsme tu pro vás. Sta?í kliknout na odkaz níže a promluvit si s agentem. Agent vám pom?že s získáním ?idi?ského pr?kazu.
Achetez un permis de conduire réel et enregistré sur notre site Web sans passer d’examens ni passer le test pratique. tout ce dont nous avons besoin, ce sont vos données et elles seront enregistrées dans le système dans les huit prochains jours. Le permis de conduire doit subir la même procédure d’enregistrement que ceux délivrés dans les auto-écoles,
zarejestrowane prawo jazdy na naszej stronie internetowej bez zdawania testów lub egzaminu praktycznego. Potrzebujemy tylko Twoich danych, które zostan? wprowadzone do systemu w ci?gu najbli?szych o?miu dni. Prawo jazdy musi przej?? tak? sam? procedur? rejestracji, jak te wydawane w szko?ach jazdy,