
We’ll call it the NoSQL Pessimism Variable: The number of search results you see before you find a page disparaging NoSQL as a viable datastore option. These pages are usually either good natured posts on why it’s a neat idea but ultimately not viable, or posts straight out slamming the platform. So too will you find the opposite; posts saying that RDBMS is the ancient past and NoSQL is the way of the future. Going by these articles you would think that RDBMS were a scourge led by Lord Sauron himself against the free peoples of Data Earth, and could only be stopped by the Fellowship of NoSQL and its distributed MongoDB Hobbit cluster.
And then of course there is the supposed animosity that exists between developers and DBAs, with DBAs thinking all developers are out to get them and developers thinking DBAs can be circumvented (but not always).
As you can probably tell from this Database Diversity series, I’m a huge fan of growth through learning about new technologies and lobbying for a place at the table. And there are of course many other forward thinkers such as Cary Milsap with his excellent article NoSQL and Oracle, Sex and Marriage (some concepts of which are included in this post). So where does the animosity come from? What is the problem some people have with NoSQL and does it have a place in our database inventory?
The ACID Test
Many articles that reference NoSQL as a poor substitute for RDBMS will bring up ACID compliance, and judging by Google there’s a lot of questions around it. So let’s take a look at ACID for a moment:
- Atomicity – A transaction as a whole either succeeds or fails, never anything in between.
- Consistency – Data must always be valid by following application logic (keys, constraints, etc)
- Isolation – No matter how much concurrency a system may have, transactions should committed and viewed in a synchronous manner
- Durability – Committed transactions must be safe in the event of a critical event
Well sorry folks, going by those definitions I’m willing to bet 99% of the actual production databases out there, RDBMS or otherwise, aren’t ACID compliant. Unless your applications perform every transaction perfectly, every column has proper constraints and error checking at all times, parameters like commit_logging are not being misused, and you can guarantee absolutely 0 data loss (not a single committed row) in the event of a nuclear strike on your data center then you’re not ACID compliant though your database system might be capable of being so.
And as Cary Milsap points out, how often is Isolation a concern anyways? How Durable is your database environment? Are you absolutely sure every required NOT NULL or UNIQUE property is actually set properly? Of course some of these things truly are a concern to some systems and thus you need ACID. Or do you?
Just because a database is NoSQL does not mean it’s not ACID compliant, and just because a system is not ACID compliant does not mean it’s not A, I, D, CID, etc. compliant. It may be that a custom combination of those four letters is all you truly need. For instance, FoundationDB promises full ACID compliance with a NoSQL engine, and systems like MongoDB, Riak, Cassandra, MarkLogic, and others can be far more durable than all but the most expensive of Oracle database environments.
No isolation? No problem! There are many times I want transactions to batch into the system and don’t really care if they’re committed or not. Some good examples are session metadata, audit information, usage history, historical data, and staging data. Load it quick and don’t worry about isolating if it gives me better performance. For that matter, forget atomicity too since I can just reload it if need be. While we’re at it, forget consistency. Some data just needs to be dumped, rules be damned.
In fact, I’d like to propose a new acronym for litmus testing NoSQL Engines: LSD:
- Limber – Flexible storage options for all types of data in multiple formats including columnar, document, key:value, or others
- Schema-less – Data need not be standardized or conformant to a strict design or datatype rules
- Distributed – Capable of spreading work over a large quantity of systems for elastic scaling when it really matters
I was going to use ALKALINE but it was just too long and K is annoying to start words with.
NoSQL at the Big Kids’ Table
NoSQL has been around for a long time, and it deserves a trusted spot in your enterprise architecture if the tool fits the need. No, you shouldn’t just migrate all of your production relational databases over to MongoDB because you read somewhere that leveraging it produced a significant ROI. But if the shoe fits, it’s your shoe. Use it when it makes sense.
Many DBAs I speak to fail to even see the reasoning behind it or why it is so popular with the development community. The pessimistic view is that developers enjoy it because they can deploy it in secret, utilizing the way of the Ninja to stealth drop it onto the server, hook their code into it, and do all sorts of conspiratorial things like efficiently query large batches of data without a single join and those pesky DBAs asking to do backups or other do-gooder stuff.
I however prefer to take a more optimistic view and say that the reason it’s so appealing is because of what it can do.
Big, Wide Rows
Have you ever had a table where a lot of descriptive details were needed in unspecified amounts, and not always guaranteed to be there? The conversation generally goes something like this:
Developer: “Alright, we need a table that can store any and all properties of items we’re selling on our website. There could be thousands or maybe none. And they’re different depending on what product it is.”
DBA: “Happy to help. Unfortunately we can’t just create a big wide table with thousands of columns. I’d suggest a table with PROPERTY_NAME and VALUE.”
Developer:DBA: “It could get to be millions of rows.”
Developer:DBA: “You should probably use PROPERTY_ID and VALUE_ID and join them to the PROPERTY and VALUE tables too.”
Developer:



Or something like that. In cases like this, it’s fairly clear where something like Cassandra seems appealing with its ability to store insanely wide rows and use data in the column name and query a slice range of those columns. Storing, querying, and joining tens or hundreds of properties for a single logical object as rows simply adds a ton of work. For instance, imagine a record describing a car sitting in a CAR table. You might have things like MAKE, MODEL, etc. to give an overall description. Now imagine you have a CAR_PROPERTIES table with every possible property a seller might want to provide: color, horsepower, intake, exhaust, seats, seat material, etc. Now I want you to write me a simple high performance query that finds all Hondas that are blue (if color is defined), with leather seats (if defined), racing stripes (if defined), and a moonroof, sunroof, or convertible (if defined).
Then there is the whole question of relational parent-child storage to begin with instead of storing logical groupings as a single document. For instance, consider a web based contact management system which must include businesses, people, contact methods, locations, and extra properties all on a single page. You’re not worried about atomicity or isolation at all, it’s just a dumping ground for contact information.
With a traditional relational database, many tables will have to be joined together to get all the data back for that page. If you want to make the page more reactive and allow asynchronous loading of various elements, you will have to program additional queries in to read/change parts of the page. If you want to build a search page that contains multiple contacts and all their associated metadata you’re in even more trouble. But with document storage offered by many NoSQL options, you can go from this:
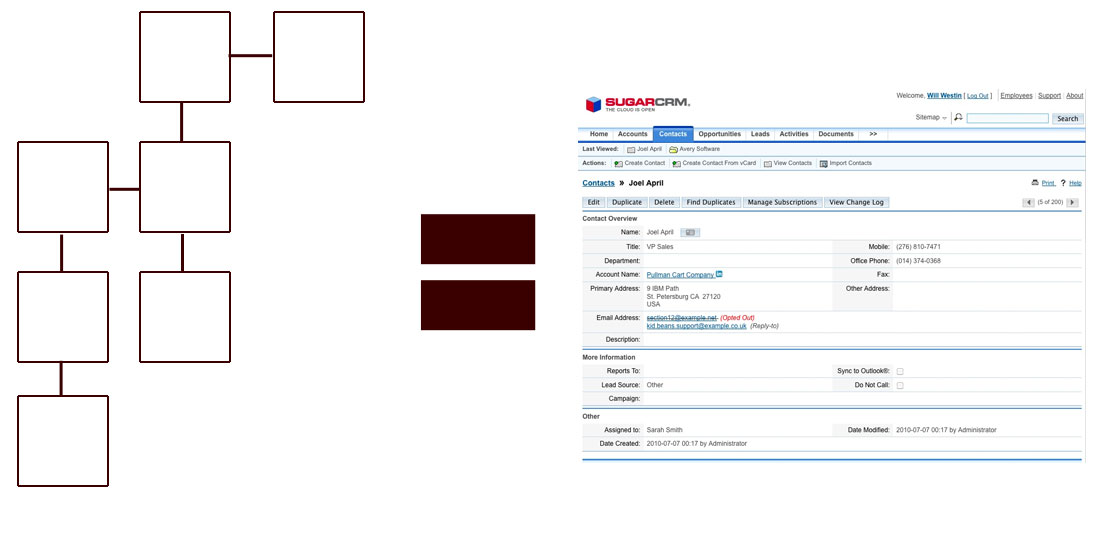
To this:

A document = A page. As simple as that. Instead of crawling through nested loops and bringing data together from a multitude of locations, logically storing a chunk of application data in its native format is appealing. Is it always the right way to do things? Of course not. But it’s extremely intuitive, easy to develop against, and can be configured for concurrency, portability, redundancy, and nearly anything else you might want depending on the NoSQL engine you’ve selected.
Conclusion
NoSQL is not THE answer, but it is absolutely AN answer. In fact, I am a strong advocate of using it together with applications that use or should use a relational model. For transactional use requiring ACID compliance (most notably atomic, sequential operations) data can be stored in the relational database. Metadata, session data, logging, metrics, and other non-transactional information that is not required for the actual end user experience can be easily stored in one of many forms offered by the various NoSQL engines.
Got a little distracted by that bit about not caring if audit information is committed or not…
Depends on the industry and the reason for auditing. But of course, some auditing is…important.
Now, this is too good a target for debunking to resist the temptation. 🙂
In order to compare NoSQL to RDBMS one must first define the NoSQL “data model”. I have yet to encounter such a definition.
And I certainly frown upon talking about relational and meaning SQL.