
Getting Into Linked Data and the Semantic Web
This is a post about the RDF metadata model and SPARQL query language, two components of the Linked Data structured data methodology. All of this is part of the collective vision known as the Semantic Web–a Web of Data that can be consumed by both humans and machines alike.
The Lay of Linked Data
And came upon a lonely datum, crying in the dark.
I said “SELECT” but she wept more, and said “that’s why I cry,
“You never thought to ask, but I spoke English this whole time.”
Relational vs. RDF Basics
Resource Description Framework (RDF) is a metadata data model in the style of a graph database whose purpose is to describe and model information found in web resources. It allows you to form incredibly descriptive relationships between entities that can be queried via a query engine called the SPARQL Protocol and RFS Query Language (SPARQL). All of these components are part of the overarching stack called Linked Data, and conceptually as the Semantic Web.
Now, before you decide to yank your computer out of the wall and flip your table over at the sheer number of different databases and query languages out there already, let me tell you that this one is pretty intuitive. And that is because it’s meant to be a descriptive way of storing data that is both human and machine readable. RDF joins together entities in ways you would expect. Let me give you an example.
{kind=link}
Let’s say in the RDBMS world, you want a table full of people, a table full of tweets and blog entries, and a table full of key terms that appear in the content. In a relational model, you’d have something kind of like this:
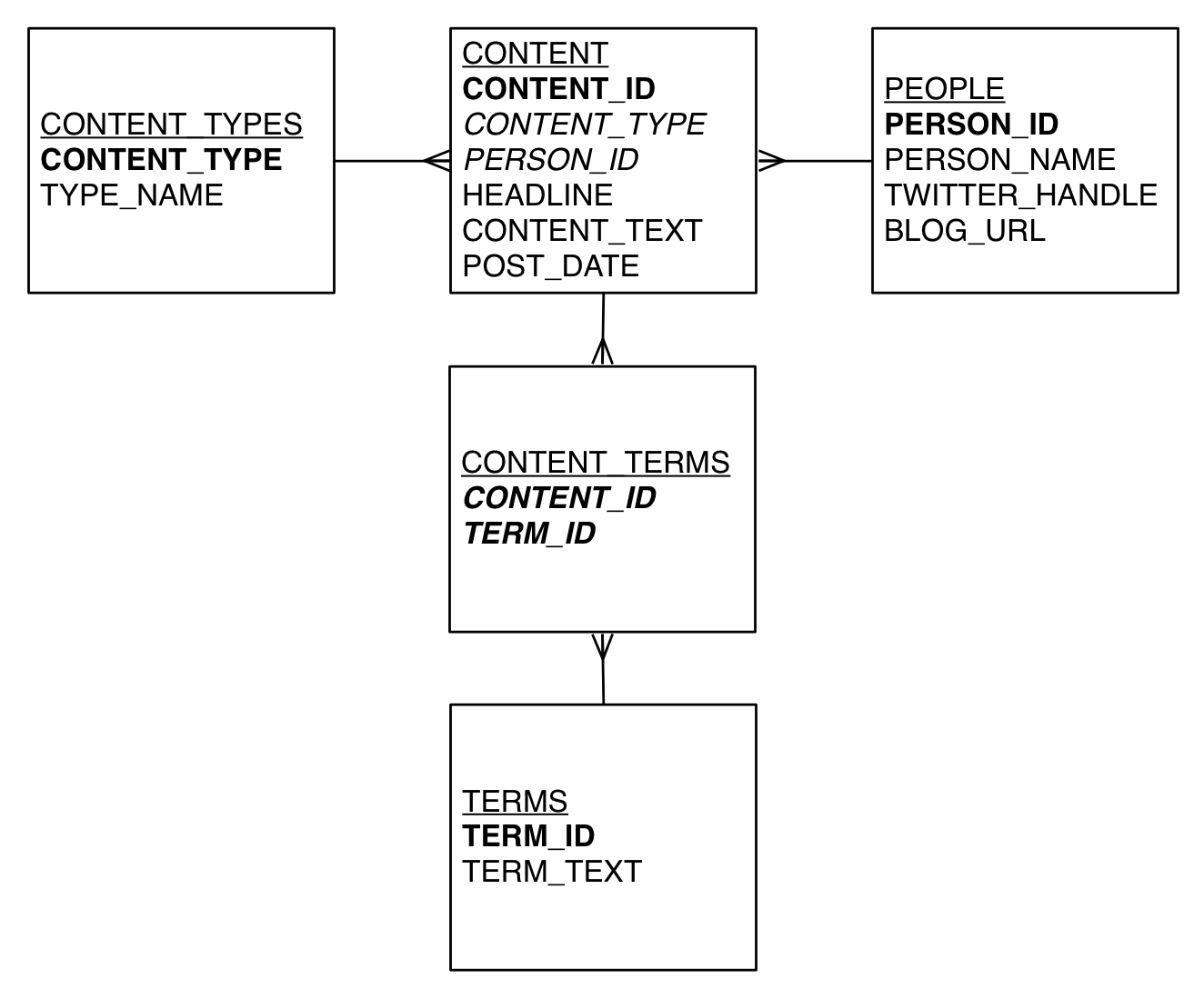
There may be many other ways to model this, but the basic ERD I’ve created here shows:
- A PEOPLE table to hold people, their names, blog address, twitter handle, etc.
- A CONTENT table to hold blogs or tweets
- A CONTENT_TYPES table to hold the different types of content (blog vs. tweet in this case)
- A TERMS table to hold the different terms that might be in a type of content
- A CONTENT_TERMS table to show which content has which terms
It’s a fairly simple design, and querying it isn’t too difficult. If I wanted to find a list of authors whose blog articles contain the word “oracle” I could run this query:
SELECT p.person_id, p.person_name FROM people p, content c, content_types ctypes, terms t, content_terms cterms WHERE p.person_id = c.person_id AND c.content_type = ctypes.content_type AND cterms.content_id = c.content_id AND cterms.term_id = t.term_id AND t.term_text = 'oracle' AND ctypes.type_name = 'blog';
You could argue that I over-normalized my design. I’d agree. But as we know, if this were to be used for a business purpose there would most likely be a whole lot more data that would be attached to each of these tables, necessitating the need for normalization to avoid over-redundancy.
Regardless, we can all agree that the model is at least queryable. But let’s say I want to find all friends of authors who write about Oracle? What about spouses of friends of authors? Authors who write about Oracle on blogs and tweets while also writing about movies on blogs (looking at you Tim)? Our queries and the data model become a whole lot more complicated and it gets very difficult to efficiently query what we need. Facebook’s graph search, for instance, is a new feature that allows these sorts of complex queries about relationships between people, photos, likes, businesses, etc. Doing such a thing on a relational database would be exceedingly difficult. But what if we could model it like this:
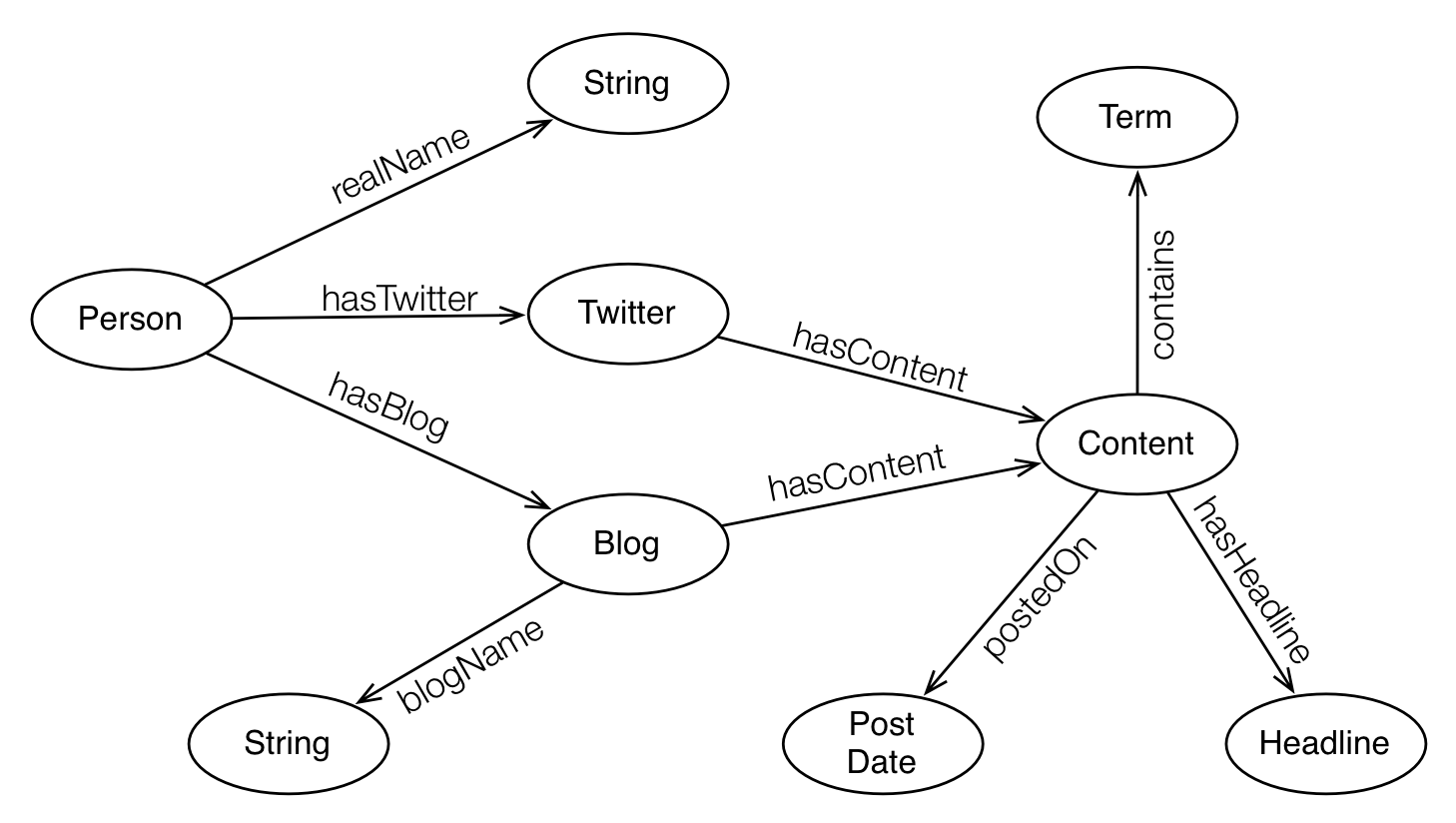
With that kind of structure, we could query not just a subject and object (entities/properties), but the predicate itself that joins them. That’s where SPARQL comes in–it is a query engine for triples, which is a three part piece of data that defines a subject, a predicate, and an object. Not only that, but with the right engine it can use inference to make queries even more flexible. For example, if “Person hasBlog Blog” (Person has a blog) then we can infer that “Person isA Author”. We can infer that “Blog isA Website”. Inference can go even deeper than that, but that’s a story for a different blog post. For now, let’s look at the data model as laid out for RDF.
Our previous requirement for a list of authors whose blog articles contain the term “oracle” would need the following sets of data from the RDF model above:
- A Person has a Blog – Person hasBlog Blog
- The Blog has a Name – Blog blogName “String”
- The Blog has some Content – Blog hasContent Content
- The Content contains a Term – Content contains Term
- The Term is “oracle” – Term termText “oracle”
- The Person’s real name is ??? – Person realName ?Person
You may notice that the ‘Term termText “oracle”‘ component is not on the original graphic. It really depends how you model it. You could make “Content contains Term (string)”, but if you ever want to attach more information about a term (importance, subject, etc.) it’s best to make it an actual property so you can add attributes to it down the line (like Blog or Person).
One other note/disclaimer: there are better ways to model this for RDF, but I’m using this method to make it easier to understand from a relational point of view.
SPARQL
SPARQL is a query language built to query triples. At the same time, it was also created to look a bit like SQL to make querying a bit easier. Personally it hurts my brain at times because the commands are similar but the format is not, but to each their own. For now, let’s just look at the SPARQL query to get the same data we were looking at above:
SELECT ?name
WHERE {
?person :hasBlog ?blog .
?blog :hasContent ?content .
?content :contains ?term .
?term :termText "oracle" .
?person :realName ?name .
}
Just some quick notes on things you may have noticed. First, all the colons. This honestly isn’t how a real SPARQL query would necessarily look. Those colons are there to denote that these properties are resources. In real RDF/SPARQL, we would be using Uniform Resource Identifiers (URIs) with various ontologies serving as namespaces in order to standardize our model. But we’ll get into that in the next article. The second thing you should notice is that there is no FROM clause. The SPARQL language does have a FROM clause, but you don’t always need it. For the most part, the SPARQL query contains a list of data you want (SELECT) and a list of bindings (WHERE). More advanced SPARQL can have things like named graphs, aggregates, and other things I’ll describe in the next article. The third thing you may notice are the periods, which are kind of like an “AND” clause and really mark the end of a triple, just like a sentence: subject predicate object.
Oh yeah, the question marks. That’s the fourth thing you may notice. The question marks are bindings, where an unknown variable is used as either a subject or object in order to locate the right data. In the example above, some variable ?term has a :hasText relationship with the string “oracle”. That ?term variable, once found, is used to find ?content that :contains the ?term. The ?content variable can be used to find the ?blog that :hasContent ?content. The ?blog helps figure out the ?person that :hasBlog ?blog. Finally, we find the name of the ?person binding, because ?person has :realName ?name. Don’t worry if you don’t get it right away. I didn’t. We’ll go through more examples in the next article.
What happens if we want to also get the blog’s name in addition to the person’s name? We can just add a new binding:
SELECT ?name ?blogname
WHERE {
?person :hasBlog ?blog .
?blog :hasContent ?content .
?content :contains ?term .
?term :termText "oracle" .
?person :realName ?name .
?blog :blogName ?blogname .
}
Since ?blog is already being used as a binding to trace back terms to people, we simply add another triple noting what else we want to bind (?blog :blogName ?blogname) and then include ?blogname in the SELECT list. When you bind something (like ?blog), you’re binding an entire resource. That resource usually will map to other things you can include quickly and easily, just like a 4 table relational join can include a 5th table with an extra WHERE clause criteria to join it in.
The bindings are incredibly powerful, and they can be used for any part of the triple–subject, predicate, or object. Think of your average WHERE clause, something like “PRODUCT_TYPE = ‘ELECTRONICS'”. With triples, we’re saying screw the simple predicates, let me say “PRODUCT is of type ELECTRONICS”. Or “CAR is colored BLUE”. With bindings, we’re saying “SELECT everything FROM everything WHERE everything everything everything”. In fact, that’s perfectly legal SPARQL:
SELECT * WHERE { ?subject ?predicate ?object }
And it would return every possible relationship (triple) you have. There are a ton of ways to take advantage of the flexibility of RDF through SPARQL.
Conclusion
RDF is a type of graph database made up of triples. Triples are three part chunks of data made like a sentence, with a subject, a predicate, and an object. Using RDF, you can define complex relationships in a way that you, your query language, and other technologies can easily understand. Similar to human language, things are described in a very granular way–down to the property level. And it’s not much different from your relational databases. Just think of your tables as Entities, your columns as Adjectives, and your relationships as Verbs. Looking at it that way, you can easily come up with triple-like notations based on any table in your database.
Thanks in advance for starting this series. I have been looking at Neo4j for some time but struggling due to my limited java skills. How different is this from Neo4j? What tools or databases are available to have a play on SPARQL and RDF?
Waiting for the following posts.
Vikram,
RDF triplestores are a type of graph database. A fully enabled graph database like Neo4J or Titan (sits on top of Cassandra or H:Base) will have many more graph oriented features like spatial queries and node traversal.
Neo4J can be used for RDF/SPARQL: http://www.neo4j.org/develop/linked_data
Hi everyone, I’m looking a way to get some rdf triplestore from facebook opengraph and make a SPARQL endpoint with that.
Have some of you any clue about where we can get the facebook open gpraph rdf dumps ? ..